Tu lances un chatbot, un agent, une automatisation IA… et là, ça met 3 secondes à répondre. 3 secondes, c’est vraiment long et l’expérience utilisateur est déjà un peu gâchée, tu l’as sûrement déjà vécu ! Dans le monde de l’intelligence artificielle, il y a deux choses très importantes : la puissance et la rapidité. Aujourd’hui, je te montre comment utiliser les modèles d’IA les plus rapides du monde, et on va les connecter à nos outils no-code Make et N8N. Et si tu es développeur, tu peux quand même utiliser leur API, hein !
https://youtu.be/O9FmXfo-qTw?si=dNXhrEmF9EBxLusi
La course à la vitesse : TTFT et Tokens/Seconde
Avant de rentrer plus en détail dans ces deux plateformes, il y a deux notions cruciales qui définissent la vitesse d’une IA :
Le TTFT : « Time To First Token »
La première, c’est ce qu’on appelle le TTFT, « Time To First Token », et c’est le temps que l’IA met pour commencer à répondre. C’est l’instant entre ton clic sur « envoyer » quand tu parles à GPT, et l’apparition du premier mot. Pour te donner une autre image, c’est le 0 à 100 km/h pour une voiture. Et plus ce TTFT sera court, plus on aura l’impression que l’IA est instantanée.
Le débit de tokens par seconde
La deuxième mesure très importante, c’est le nombre de tokens par seconde. Pour rappel, un token, c’est un mot ou un morceau de mot. Plus le nombre de mots par seconde, le nombre de tokens par seconde, sera élevé et plus ça sera rapide de générer, de créer un texte long.
Pour te donner un ordre d’idée, une vitesse de 10 tokens par seconde, ça équivaut à environ 450 mots par minute, ce qui est plus rapide que la vitesse de lecture moyenne par un être humain.
L’analogie de la cuisine
Pour te donner une dernière image, si tu es dans une cuisine :
- Le TTFT, c’est le temps que va mettre la cuisine à t’envoyer ton entrée après avoir fait ta commande.
- Par la suite, le nombre de tokens par seconde, c’est la cadence, c’est la vitesse à laquelle les plats suivants vont arriver sur ta table, donc ton plat principal, ton dessert, etc.
Tu l’as compris, un TTFT faible et un nombre de tokens par seconde élevé donne l’impression d’avoir une IA très rapide. Évidemment, ces deux paramètres ne sont pas du tout liés à la puissance de l’intelligence artificielle. Tu peux avoir une IA très puissante et très rapide, ou une IA pas très puissante et très lente.
Groq et Cerebras : Les champions de la rapidité
Pour te donner une idée des performances actuelles, je suis allé sur le site Artificial Analysis, qui permet d’avoir des analyses sur les IA.
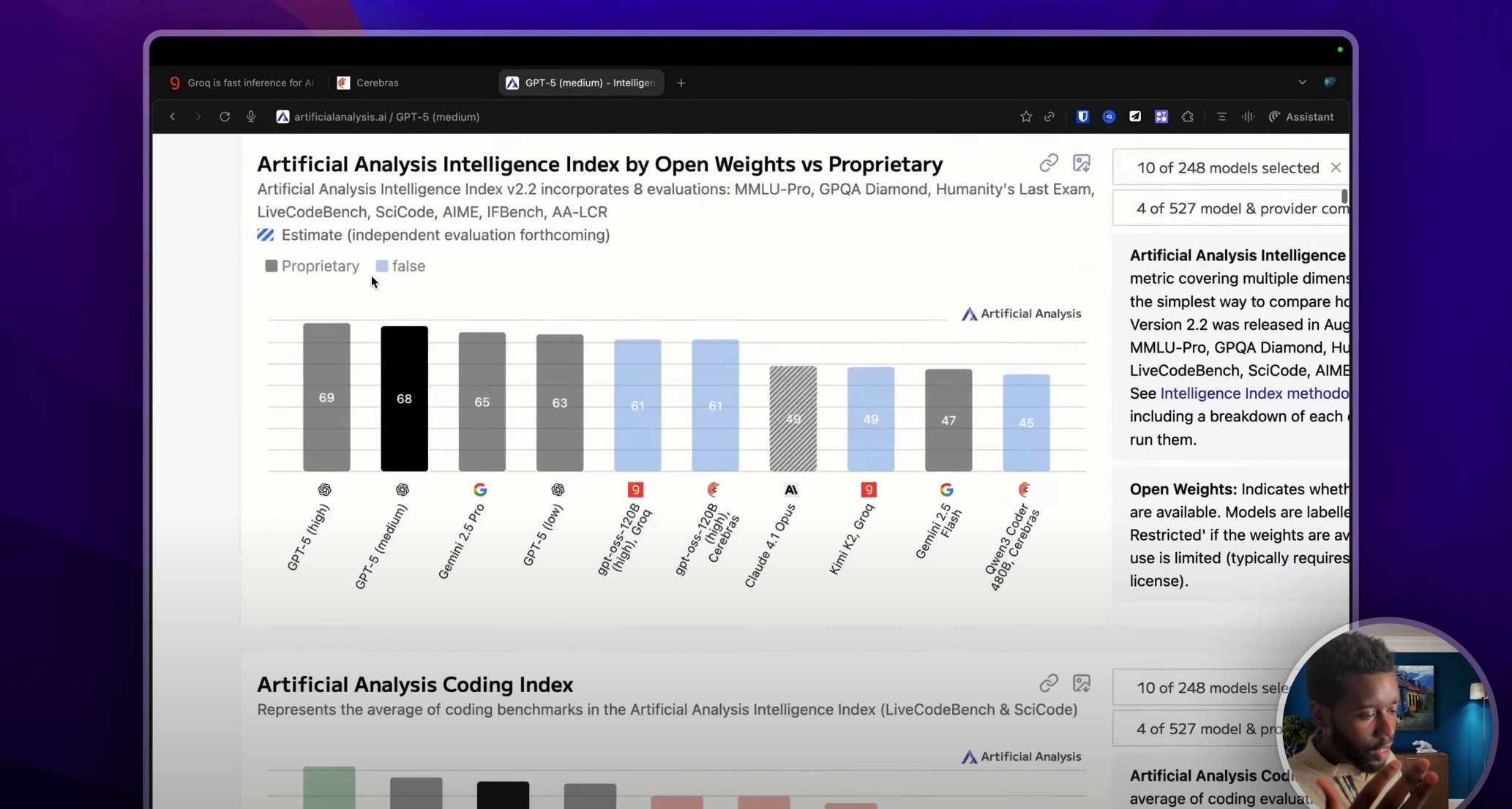
On va aller descendre tout en bas pour aller voir ce tableau. Si c’est possible, je mettrai le graphique dans la description, mais sur l’axe des ordonnées, tu peux voir le TTFT en seconde, et sur l’axe des abscisses, tu peux voir le nombre de tokens par seconde. En d’autres termes, plus une IA se trouve dans la partie basse de cette zone verte, plus elle sera rapide.
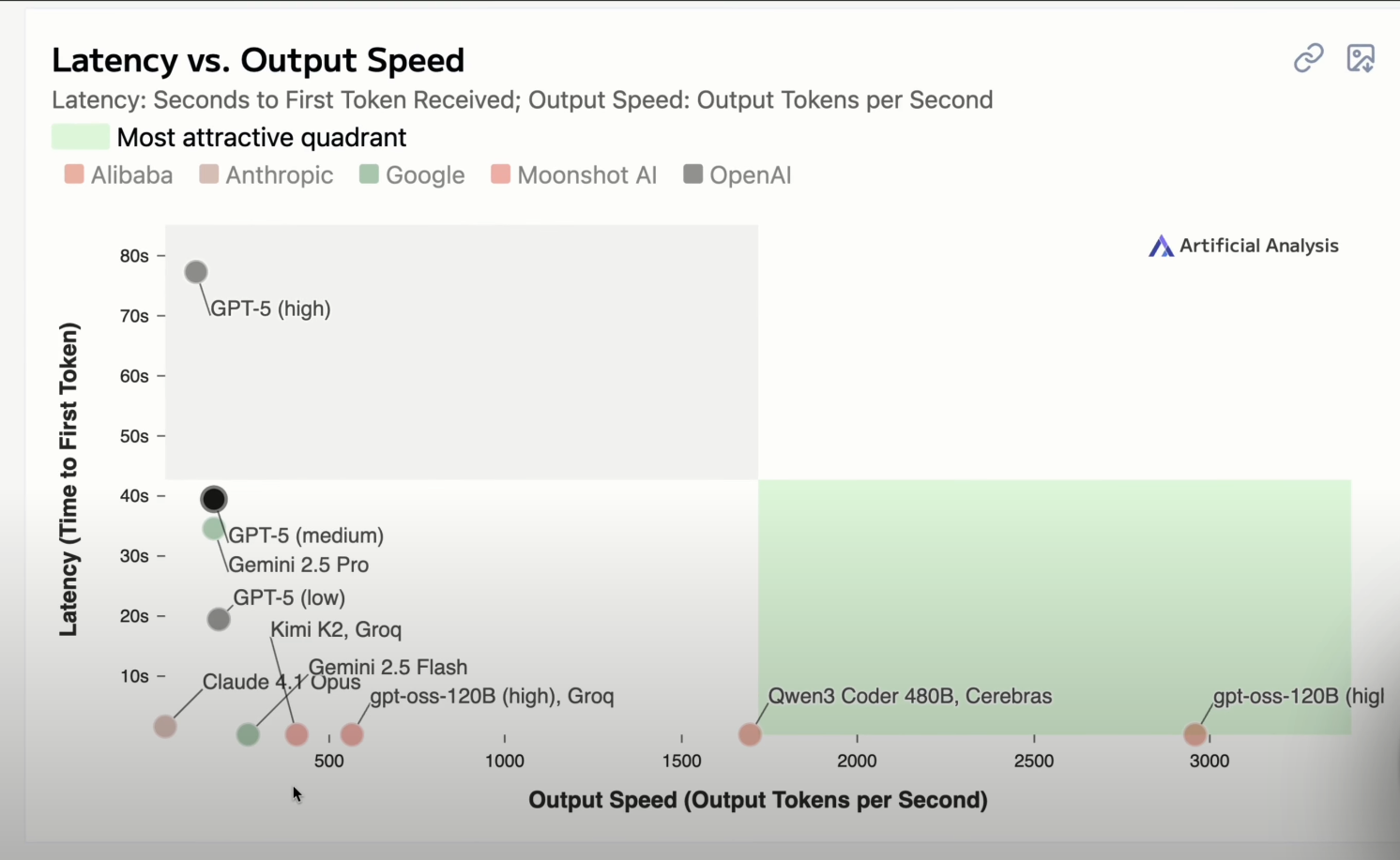
Sur ce graphique, j’ai voulu comparer les modèles fournis par Groq et Cerebras – deux fournisseurs d’IA infiniment rapides – avec les modèles que tu connais comme GPT-5, Gemini de Google qui est juste ici, ou encore Claude d’Anthropic.
Par exemple, si on prend Gemini 2.5 Pro de Google, qui est un modèle de raisonnement, on peut voir qu’il a un TTFT de 34 secondes (évidemment, tout ça ce sont des moyennes). Et ce même modèle envoie à peu près 172 tokens par seconde.
Alors que si on regarde GPT OSS, qui est un modèle open source fourni par OpenAI mais qui est hébergé par Groq, cette fois-ci on a un TTFT de 0.2 secondes pour, par la suite, envoyer plus de 500 tokens par seconde ! Et le constat sera le même si tu compares des modèles plus traditionnels comme GPT-5, Claude, et ainsi de suite.
Cela étant dit, à l’heure où je tourne cette vidéo, le champion de la vitesse, c’est la version GPT OSS 120 milliards de paramètres fourni cette fois-ci non pas par Groq, mais par Cerebras, qui répond en 0.2 secondes avec un nombre de tokens par seconde presque à 3000 ! C’est le modèle de cette taille le plus rapide du monde.
Petite précision : dans ce tableau, j’ai comparé des modèles open source de grande taille comme GPT OSS ou encore Llama-2. Ces modèles, on connaît leur taille, contrairement aux modèles propriétaires en général (en tout cas), comme GPT-5, Gemini ou Claude, on ne sait pas quelle taille ils font. En tout cas, ce ne sont pas des données très publiques, mais je trouve quand même que ça donne un ordre d’idée. C’est pour ça que j’ai fait cette comparaison, hein.
Comment font-ils pour être aussi rapides ?
Maintenant, la question légitime que tu pourrais te poser, c’est : comment font-ils pour être aussi rapides ?
Si on reprend l’approche traditionnelle, les entreprises qui fournissent des modèles d’IA utilisent des GPU. Ce sont des cartes graphiques qu’on utilise depuis bien longtemps dans nos ordinateurs pour afficher des éléments graphiques, pour faire tourner des jeux, et depuis peu pour entraîner et faire tourner des modèles d’IA. Et ces entreprises utilisent énormément de GPU qui n’ont pas été à la base créés pour l’IA, mais bon, ça fonctionne donc on les utilise.
Mais Cerebras et Groq, dès leur création respectivement en 2015 et en 2016, ont décidé de prendre le contrepied de l’industrie, en créant des puces spécialement faites pour l’intelligence artificielle.
D’ailleurs, pour la petite anecdote, Cerebras a été créé par Andrew Feldman en 2015, juste après qu’il ait vendu son ancienne société à AMD, qui est un géant des processeurs et des cartes graphiques. Quant à Jonathan Ross, lui il travaillait chez Google dans la partie hardware, dans la partie processeur, carte graphique.
Et donc ces deux messieurs ont créé respectivement leur propre puce spécialisée en IA. Pour Cerebras, c’est la WSE (on va parler avec les acronymes), et pour Groq, c’est la LPU. Elles ont chacune leurs spécificités. Retiens simplement qu’elles sont faites pour l’IA. Si tu as envie que je détaille pourquoi elles sont plus rapides, n’hésite pas à me le dire en commentaire, j’en ferai une autre vidéo !
Comme je te l’ai dit, sur Cerebras et sur Groq, tu as accès à des modèles open source comme Mistral, Llama, le modèle de Meta, ou d’autres modèles comme Whisper, qui permet de faire du speech to text, de l’audio vers du texte. Et tous ces modèles sont exécutés sur les puces que tu as vues précédemment, ce qui permet d’avoir des réponses hyper soniques.
Les prix
Maintenant, si on regarde les prix, les deux te permettent d’utiliser leur modèle en payant au token, qui est la tarification de base dans le monde de l’intelligence artificielle.
D’après les analyses que j’ai faites, Groq sera relativement moins cher que ses concurrents. Je te mettrai les prix dans la description.
Pour Cerebras, c’est la même chose. Tu pourras accéder à un tableau des prix, même s’il est fort probable que tu n’utilises pas Cerebras en passant par leur site internet, car ils visent les clients entreprises. Si tu te rends sur leur site, tu verras des forfaits assez chers, plusieurs milliers de dollars par mois.
Mais il est possible d’utiliser Cerebras en passant par d’autres fournisseurs comme Hugging Face ou Open Router.
Démos sur Make et N8N
Je te propose maintenant de passer aux démos sur Make et N8N.
Utiliser Groq
Pour Groq, deux choix s’offrent à toi :
- Soit tu passes par la plateforme de Groq. Il faudra que tu t’inscrives (moi je suis déjà inscrit, je te laisserai le faire).
- Ou soit tu peux également passer par Open Router (on va utiliser Open Router pour Cerebras dans quelques minutes).
Comme sur toutes les plateformes, tu pourras voir ton usage, tu pourras avoir accès à un playground pour faire des tests. Par exemple, là, je peux écrire « hello » et j’ai une IA qui m’a répondu.
Tu pourras aller dans les paramètres si je vais dans « Upgrade » pour accéder à mon forfait, rajouter ta carte bancaire si c’est nécessaire. Mais dès l’inscription, tu seras dans le forfait gratuit, grâce auquel tu pourras bénéficier d’un certain nombre de tokens gratuits. Mais évidemment, si tu commences à utiliser Groq dans des vraies applications, tu seras rapidement limité. Donc je te conseille de passer au forfait développeur.
Génial, on est inscrit ! On va pouvoir aller dans « API » pour créer une clé API qu’on utilisera sur N8N et sur Make.
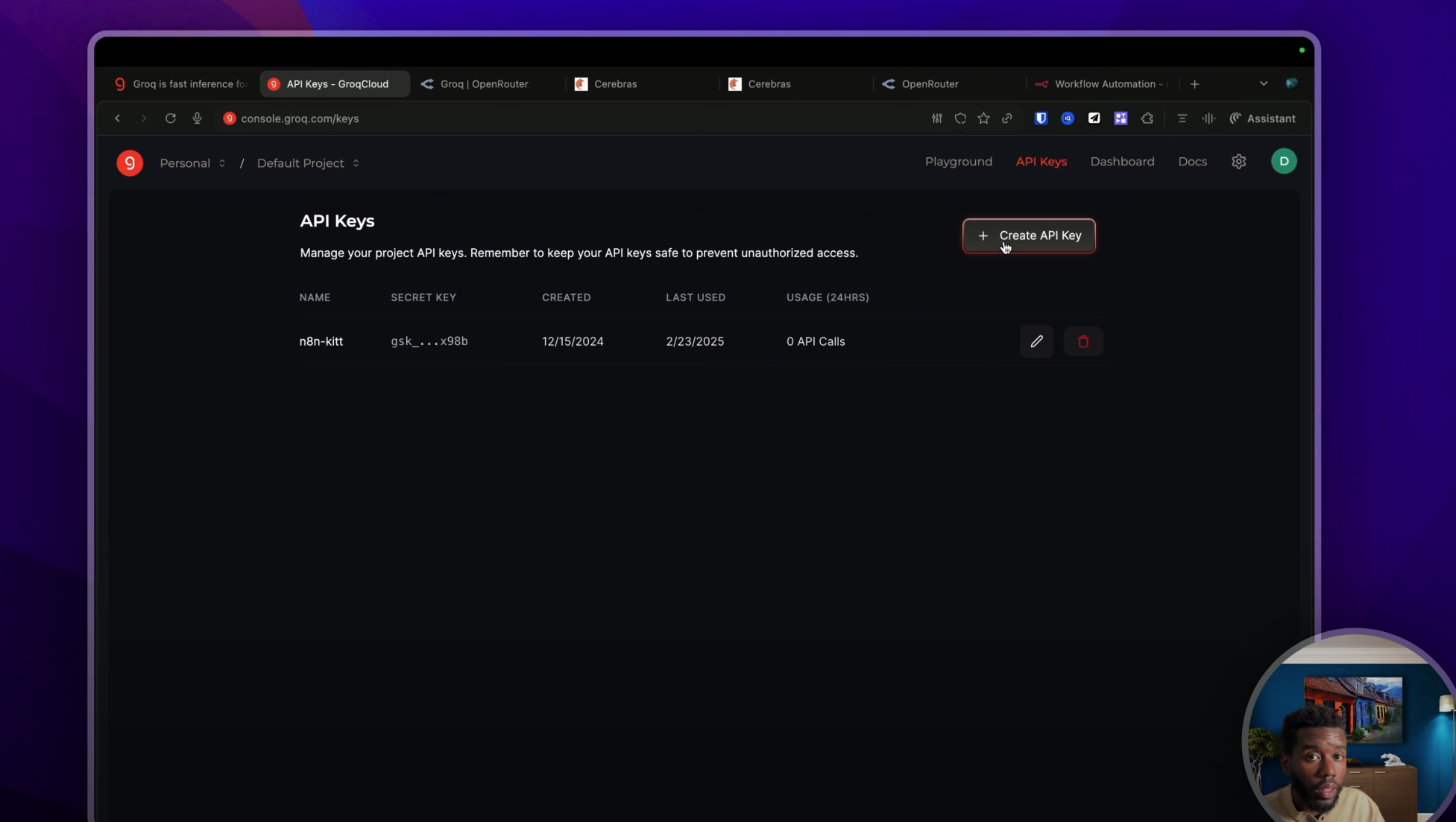
Il te suffit de la nommer « test » par exemple, de la récupérer et de te rendre sur N8N dans un nouveau workflow.
Groq avec N8N
Si tu souhaites utiliser Groq dans une automatisation classique, il te suffira de taper « Groq chat model » par exemple.
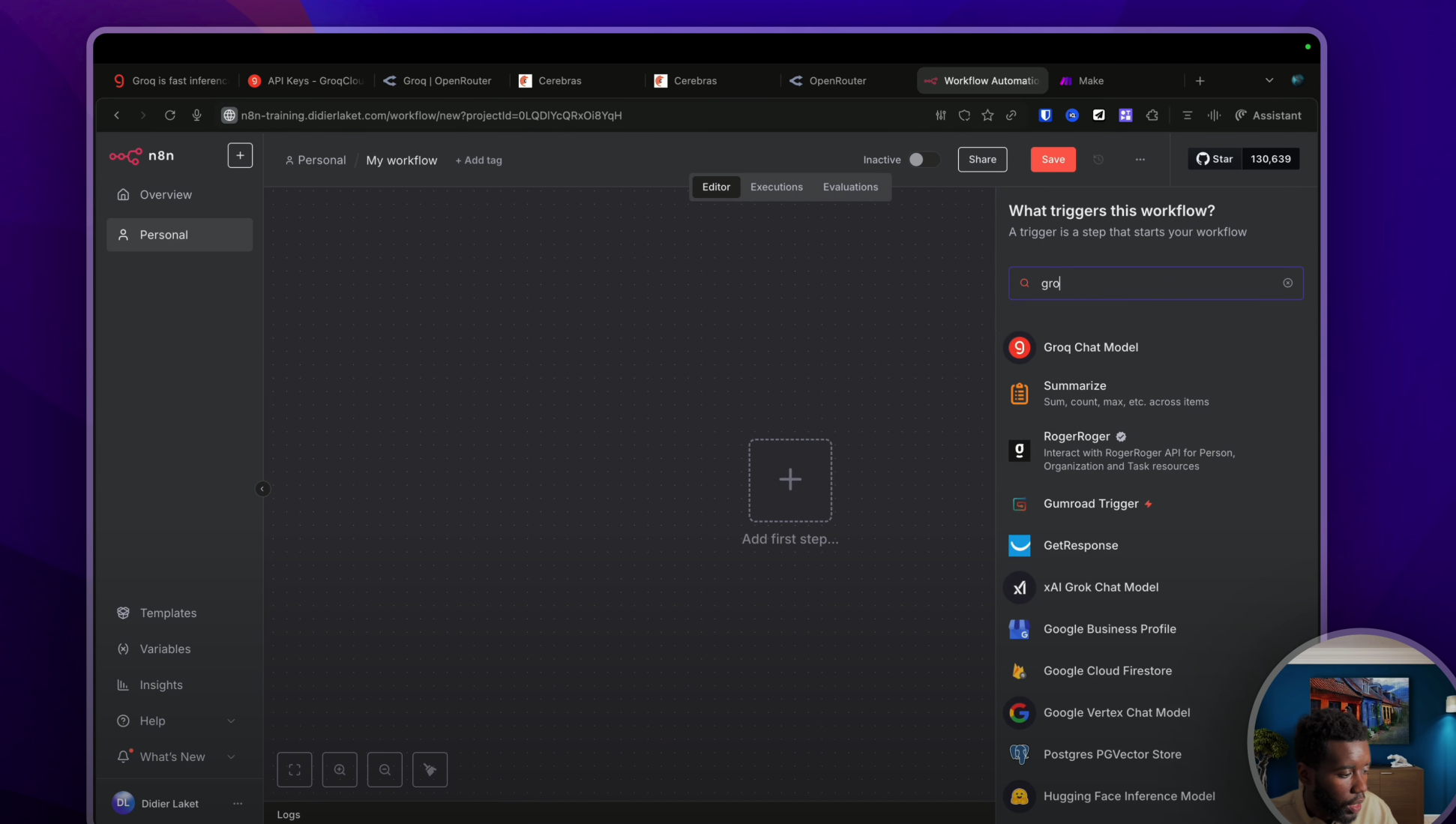
Puis de cliquer sur « Create and Show » pour créer ta connexion API comme ceci. Là, j’ai collé la clé API que je viens juste d’avoir. On va sauvegarder. Hop, la connexion a été faite. Je peux la tester de nouveau. Génial. Et là, j’ai accès à la liste de tous les modèles que tu as vus très rapidement dans les listes précédentes. Et je peux par exemple prendre GPT 12 milliards de paramètres comme ceci.
Et commencer tout simplement à discuter. Hop ! Hello. Génial, j’ai reçu une réponse. « Quelle est la biographie de Victor Hugo ? » Et là, on a une réponse assez longue en quelques secondes.
Ça, c’est la première méthode. Par la suite, si tu veux utiliser Groq avec un agent sur N8N, il te suffira tout simplement de cliquer sur le nœud « agent IA ».
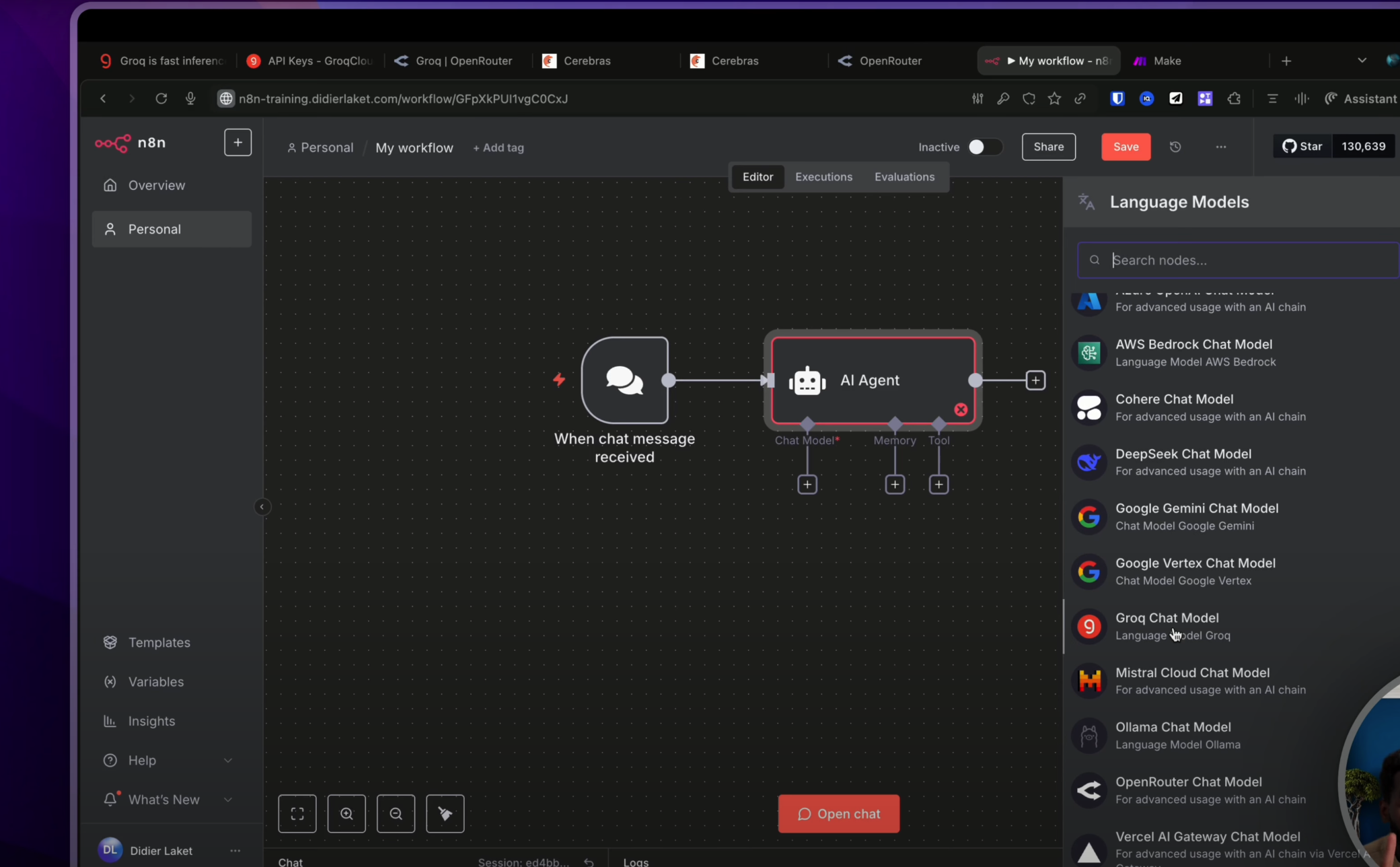
Puis d’aller choisir ton chat model afin d’utiliser Groq, qui est également dans la liste juste ici. Hop. Étant donné que j’ai déjà fait ma connexion, je n’ai pas besoin de la refaire. Et je peux comme tout à l’heure sélectionner le modèle de mon choix, GPT OSS 120B. Et comme tout à l’heure, je vais pouvoir discuter avec mon agent. « Quelle est la biographie de Marie Curie ? » Et en quelques instants, la voici !
Groq avec Make
Maintenant, si on souhaite utiliser Groq sur Make, deux possibilités s’offrent à toi encore une fois :
- Soit tu l’utilises dans un workflow IA classique. Donc là, on va appeler un nouveau nœud. D’ailleurs, j’ai créé un nouveau scénario. Je vais prendre le module spécifique Groq, et je vais pouvoir sélectionner l’action de mon choix. Il y a pas mal d’actions : analyser une image, faire de la transcription audio… D’ailleurs, ça c’est une des différences pour l’instant, au moment où je tourne cette vidéo, entre Groq et Cerebras. Sur Cerebras, il n’y a pas de modèle de transcription.
Donc là, par exemple, je peux prendre « Chat Completion ».
Encore une fois, je vais devoir créer une connexion. Ici, j’ai plus qu’à coller ma clé API de tout à l’heure. « Groq test » comme ceci. Hop, je sauvegarde. La connexion a été faite. Je vais pouvoir sélectionner le modèle de mon choix comme d’habitude et commencer à discuter en envoyant un message.
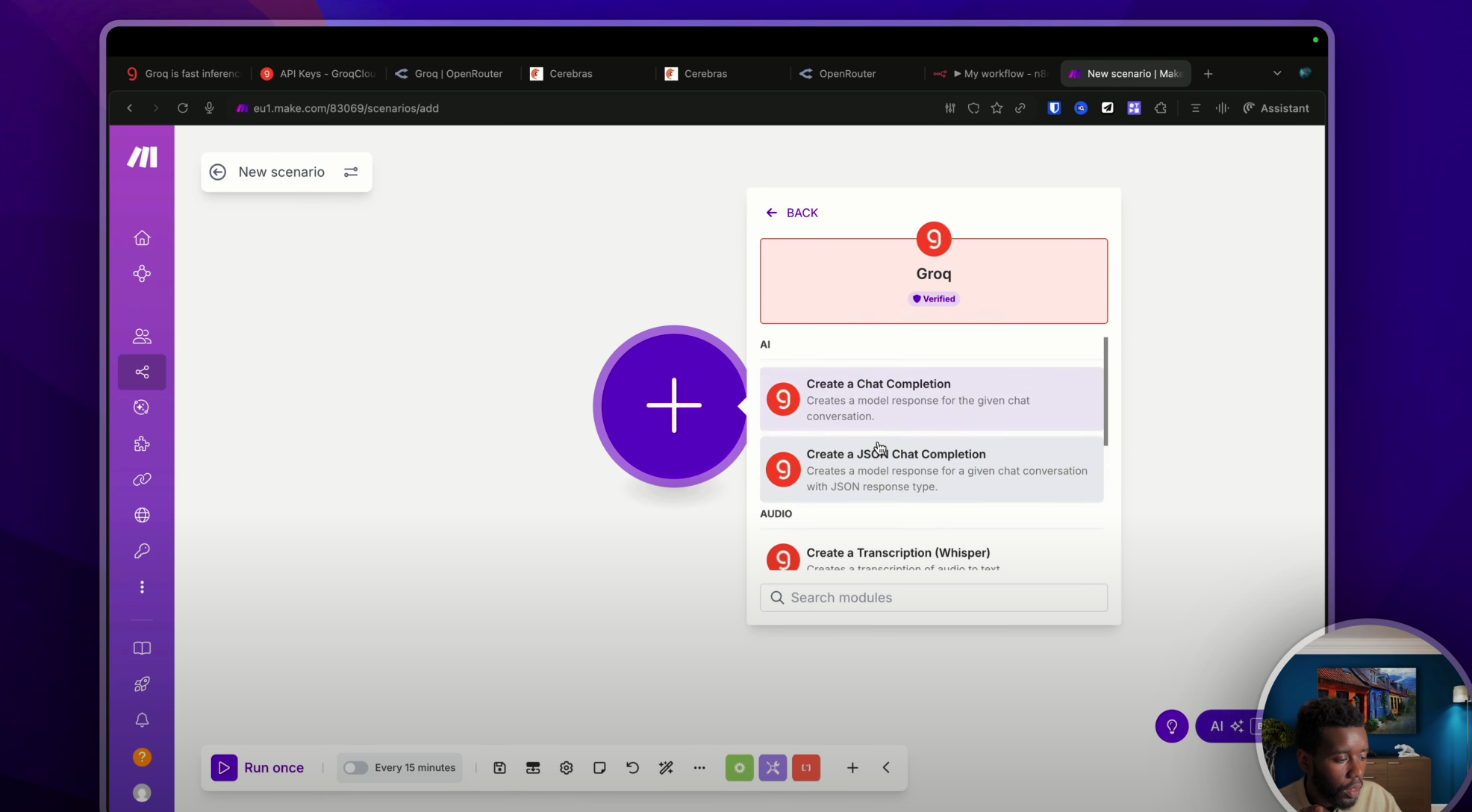
« La biographie de Victor Hugo. » Et voilà le résultat. Je pense que c’est mon choice message content. « Voici la biographie. Génial. »
- Maintenant si je veux utiliser Groq avec un agent IA, il me suffira de me rendre dans la section « Agent IA », de créer un nouvel agent, d’ajouter une connexion et de sélectionner dans cette liste Groq, qui est déjà présent également. Génial.
Je colle encore une fois ma clé API. Hop. Agent. Je nomme mon agent : « Test ». Je mets un système prompt : « Tu es un assistant. » « Test 2 ». Apparemment le nom de mon agent existait déjà. Et là, je vais pouvoir lui parler : « Hello, la biographie de Victor Hugo. »
En quelques secondes, la réponse a été faite. Encore une fois, en sauvegardant cet agent, je vais pouvoir l’utiliser dans n’importe quel scénario en cliquant sur « Agent », en faisant « Run Agent » et en sélectionnant « Test 2 ».
Voilà, on a utilisé Groq avec N8N et Make.
Utiliser Cerebras
Je te propose de passer maintenant à Cerebras. Comme je te l’ai dit précédemment, Cerebras vise un peu plus les entreprises, mais on peut quand même utiliser ses modèles en passant par Open Router ou Hugging Face. Nous, on va prendre Open Router. Si tu ne sais pas ce qu’est Open Router, j’ai fait une vidéo qui est normalement sortie et le lien est dans la description, où je te présente cette super plateforme.
En quelques mots, c’est une plateforme grâce à laquelle tu vas pouvoir utiliser n’importe quel modèle d’IA sur le marché, avec potentiellement des fournisseurs différents. Je vais tout expliquer, mais avant ça, je te conseille de t’inscrire sur openrouter.ai afin de pouvoir commencer à l’utiliser.
Si je me rends par exemple sur GPT OSS comme ceci, comme tu le sais, on l’a dit dans la vidéo, c’est un modèle open source, et ce modèle est hébergé et fourni par différents fournisseurs. Ici, j’ai DeepInfra, nCompass, Baseten, ainsi de suite.
Et c’est le cas pour tous les modèles, sauf les modèles propriétaires. Je pense à GPT-5 qui doit être exécuté uniquement sur les serveurs d’OpenAI ou de Microsoft. La tarification sur Open Router sera par millions de tokens comme sur toutes les autres plateformes.
Pour l’utiliser, tu devras te rendre dans « Crédits » afin d’ajouter un certain nombre de crédits. Donc ici, il te suffira de mettre ta carte bancaire et d’ajouter quelques euros afin que lors de l’utilisation de tes modèles, Open Router puisse aller piocher dans ta cagnotte.
OK, on a mis nos crédits. Maintenant, il nous reste à générer une clé API comme d’habitude. Donc, on va aller se rendre dans cet onglet. On va cliquer sur « Créer une clé API ». Encore une fois « test vidéo ». Tu auras différentes options comme des limites, ainsi de suite.
Cerebras avec N8N (via Open Router)
Je vais pouvoir me rendre sur un workflow N8N par exemple. On va commencer par N8N. Et là, si tu cherches Cerebras, évidemment il n’y aura pas de nœud N8N. Donc tu devras prendre le nœud Open Router comme ceci. Open Router chat model. C’est exactement la même chose que tu as vue précédemment dans la partie Groq. Tu vas devoir créer un crédit, mettre ta clé API comme ceci, la sauvegarder, ainsi de suite. Bon, moi je l’ai déjà, donc je vais pas la sauvegarder de nouveau. Et ici, tu pourras choisir dans les modèles disponibles sur Open Router. Donc nous on va dire GPT OSS et on pourra sauvegarder.
Et là, c’est exactement la même chose que tout à l’heure. Tu vas pouvoir commencer à discuter simplement. Il y a potentiellement plusieurs fournisseurs d’IA pour chaque modèle d’intelligence artificielle sur Open Router. Donc il va falloir que tu fasses une petite modification dans tes paramètres.
Donc on va se rendre dans « Settings » puis dans « Account ». Et dans « Account », tu as normalement un menu qui s’appelle « Allowed Providers », qui signifie les fournisseurs d’intelligence artificielle que tu souhaites autoriser. Et juste ici, il ne te restera plus qu’à indiquer Cerebras comme ceci.
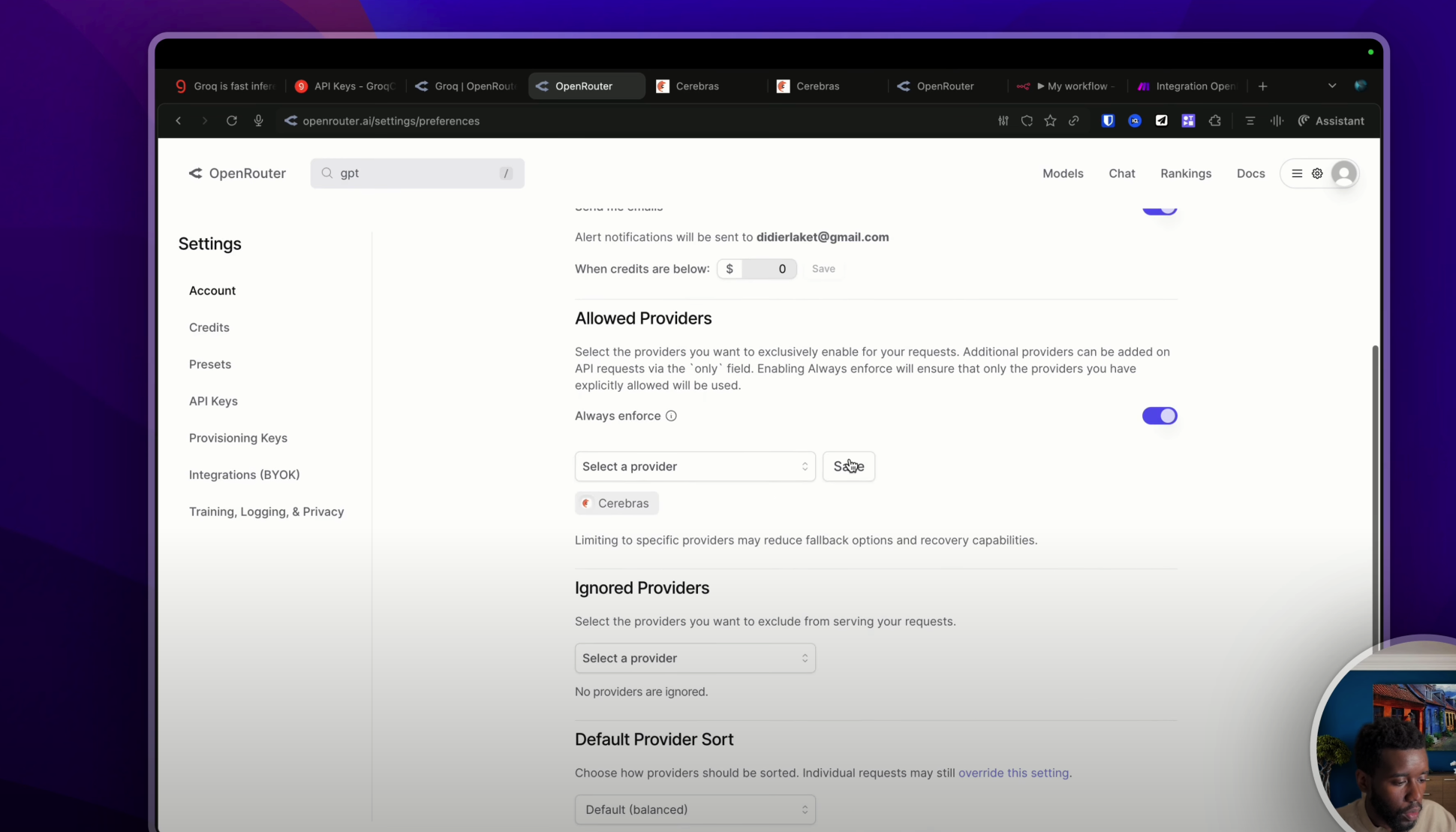
Hop, tu pourras faire sauvegarder. Et la dernière modification, si tu ne souhaites utiliser que Cerebras avec ton compte Open Router, il faudra que tu actives cette option « Always enforce » qui va faire en sorte de n’utiliser que Cerebras. Il y a évidemment d’autres options en termes de fournisseur d’intelligence artificielle. Tu peux décider d’en ignorer. Par exemple, je pourrais ignorer très bien le Groq si je le souhaite et sauvegarder. Bon, ça n’a pas trop de sens étant donné que j’ai dit que je ne voulais utiliser que Cerebras juste ici. Mais c’est possible.
D’ailleurs, petite astuce, si tu souhaites savoir si tel ou tel fournisseur fournit tel ou tel modèle (une phrase un peu compliquée), et bien il te suffit simplement de taper le nom de ton provider dans la barre de recherche. Par exemple, « Cerebras » comme ceci. Hop. Et ici, si je descends déjà, j’ai son activité en terme de tokens sur la plateforme.
Donc c’est la combinaison de l’utilisation de tous les utilisateurs de Cerebras sur Open Router. Et juste en dessous, j’ai la liste de tous les modèles fournis. Évidemment, si tu as utilisé un modèle qui n’est pas présent dans cette liste, mais que tu as forcé l’utilisation de Cerebras, ça ne sera pas Cerebras qui sera utilisé mais un autre fournisseur.
Par la suite, pour t’assurer que c’est bien Cerebras ou Groq ou le fournisseur de ton choix qui a été utilisé, tu peux te rendre dans « Activity » comme ceci. Ici, on a toutes nos utilisations des modèles d’Open Router avec leur fournisseur, ainsi de suite. Ma dernière requête était à 6h21 apparemment.
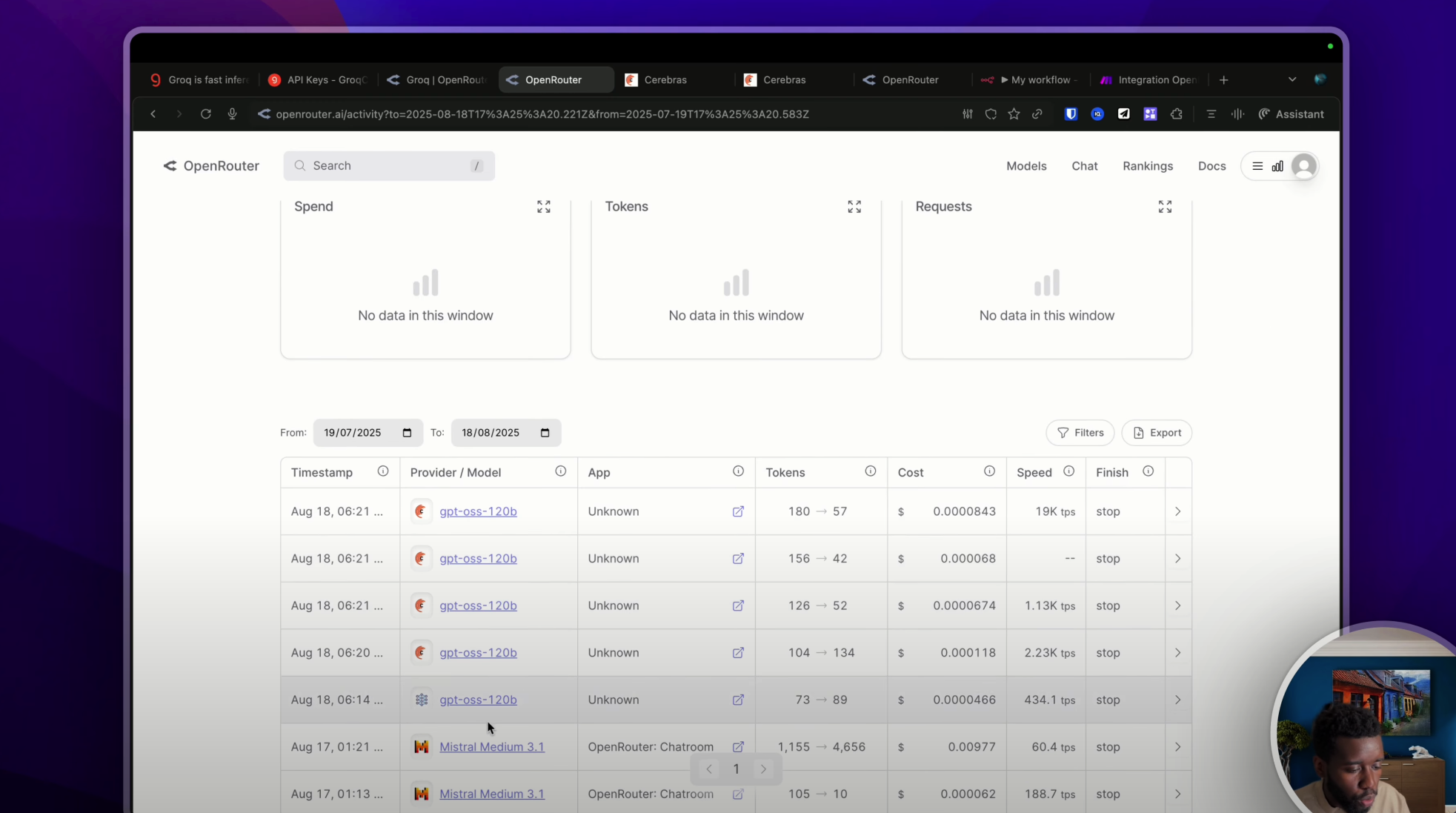
Donc là, si je fais un petit « hello », normalement je devrais avoir une réponse. C’est vraiment rapide. Et si je rafraîchis cette page, 7h25, et je vois bien que le provider est Cerebras.
Bon, maintenant, tu connais la logique. Ici, j’ai utilisé un nœud IA basique, mais si je souhaite utiliser un agent IA avec Cerebras, il me suffira d’appeler un agent IA comme ceci et de rattacher le petit Open Router à mon agent pour utiliser Cerebras.
Cerebras avec Make (via Open Router)
Je te propose de faire ces manipulations sur Make. Et donc pour ceci, on va se rendre sur Make. Une fois que tu seras sur Make, pour utiliser Cerebras, il te suffira de créer une nouvelle automatisation, de cliquer sur Open Router. D’ailleurs, petite note, mais il existe un module Cerebras, je te déconseille de l’utiliser parce que tu seras obligé d’utiliser la clé API de ton compte Cerebras. Donc si tu n’en as pas un, il faudra en créer un. Mais mise à part, si tu payes un abonnement mensuel à Cerebras, tu seras dans le forfait le plus bas qui a énormément de limitations. Donc je te conseille vivement de passer par Open Router.
Donc nous on va passer par Open Router comme ceci. Rebelote. Maintenant tu dois choisir l’action de ton choix. Donc on va créer un « Chat Completion ». On va créer une connexion, on va sélectionner « Open Router Classic » comme ceci avec une clé API. Là, il faudra que tu colles ta clé API de tout à l’heure comme ceci. Hop, la colle. Et voilà, ça fonctionne.
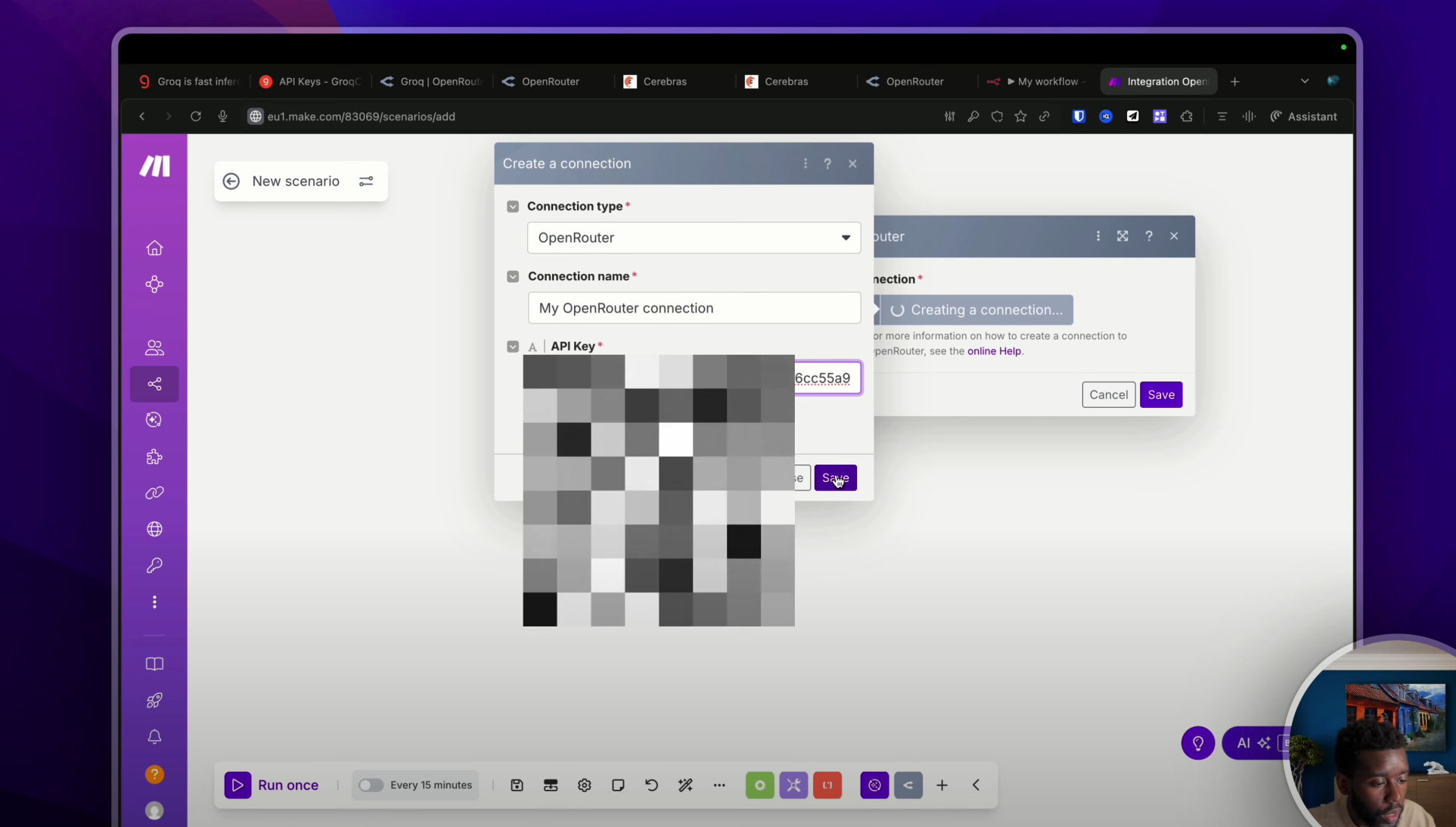
Maintenant, il me suffit de chercher le modèle de mon choix, encore une fois en ayant activé l’option de l’unique provider de tout à l’heure. Et normalement, si je discute, alors là, je vais rajouter un petit message, on va dire « Hello, je veux la biographie de Victor Hugo ».
Si j’exécute ce nœud, j’aurai une réponse normalement assez rapide. Bon là, je pense que ça prend du temps parce que c’est côté de Make, non ? C’est un peu plus rapide. Le choix. Hop ! Message et dans le contenu, j’ai bien la biographie. Et si je regarde dans l’Activity, encore une fois, c’est Cerebras qui a été utilisé.
Maintenant, si je souhaite utiliser Cerebras avec les agents IA de Make, il te suffira de te rendre sur « Agent IA », de créer un nouvel agent, de créer une nouvelle connexion comme ceci, d’aller chercher dans la liste, d’aller chercher la dernière option « Autre provider compatible avec Open AI API ».
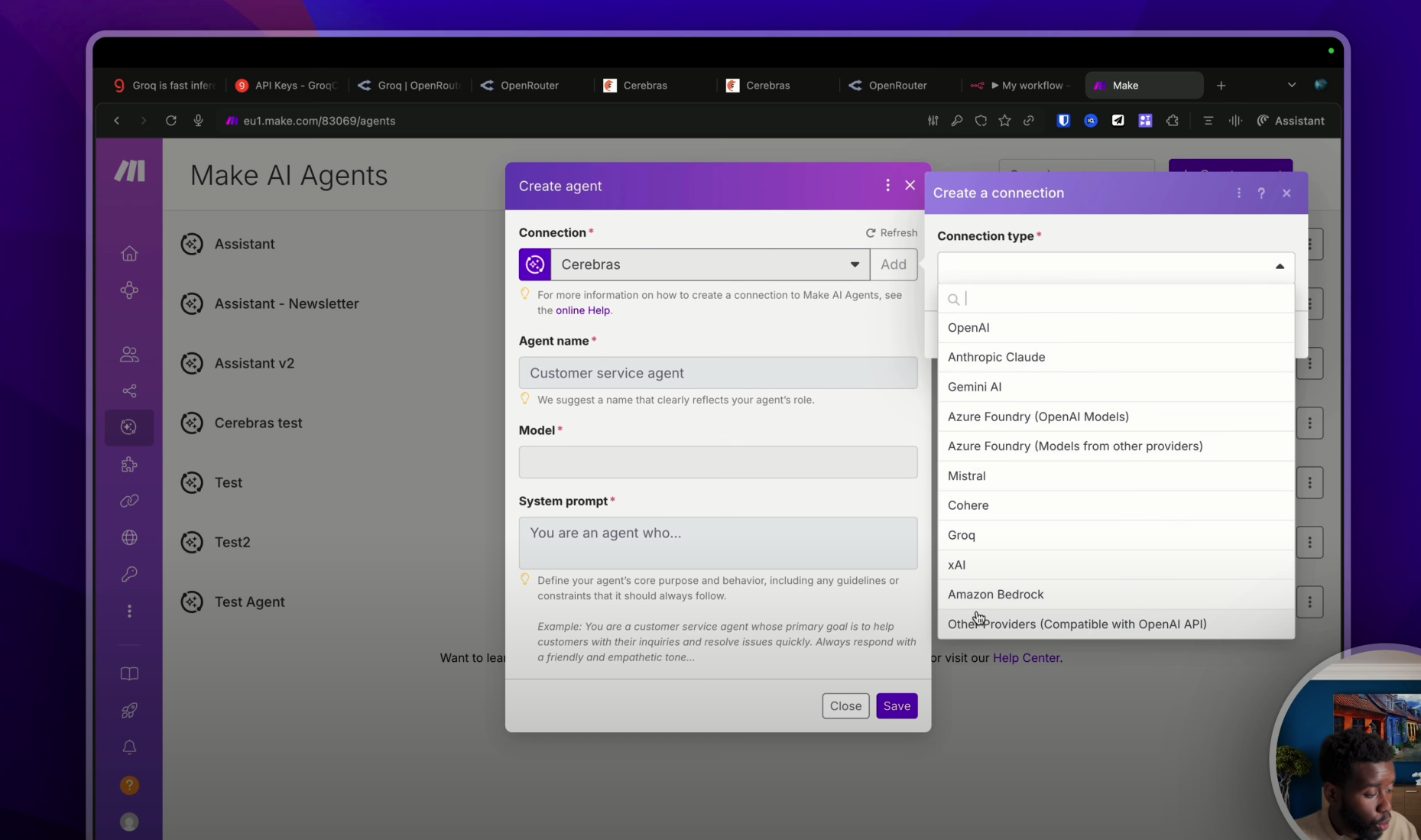
Dans l’API Key, on va coller la clé API de tout à l’heure, et puis dans la « Base URL », on va indiquer l’URL d’Open Router. Pour trouver l’URL d’Open Router, il te suffit soit de te rendre dans la documentation d’Open Router (donc si elle n’est pas inscrite ici comme c’est le cas juste maintenant, bah il te suffira de cliquer sur enfin d’aller sur Google, de dire « Open Router documentation API » et de trouver cette URL là qui nous permettra de faire des requêtes, d’utiliser les modèles d’Open Router). Mais bon, on a de la chance, le lien est juste ici. Donc on va prendre ce lien, on va le coller juste ici. On va faire « Save ».
Et voilà, on a bien notre connexion avec Open Router. On va mettre un nom à notre agent : « Test 4 ». Sélectionner le modèle de notre choix. Mais là, comme tu le vois, ce n’est pas une liste prédéfinie parce que Make n’est pas au courant de tous les modèles disponibles sur Open Router dans ce cas de figure là.
Donc ce qu’on va faire, c’est qu’on va retourner sur Open Router. On va aller sélectionner le modèle de notre choix. Donc on va prendre « GPT OSS 120B ». Et là, ce que tu vas faire, c’est que tu vas coller la petite phrase qui est juste ici avec ce petit bouton. Cette phrase correspond à l’identifiant du modèle.
Donc si je change de modèle, par exemple GPT-5, j’ai exactement la même phrase, ou Gemini, par exemple. Chaque modèle a son petit identifiant, et c’est cette phrase que tu dois copier. D’ailleurs, si tu te souviens bien, que ça soit sur N8N ou même sur Make tout à l’heure, on avait exactement la même phrase, tu vois là, le modèle.
OK, donc maintenant on aura simplement à indiquer le modèle, ni plus ni moins. Ne rajoute rien d’autre par la suite, sinon ça ne va pas marcher. Et tu pourras indiquer ton système prompt : « Tu es un assistant. » Normalement, j’ai pas fait de faute. Et là, on va pouvoir tester notre agent. « Hello. » Normalement, ça marche. Génial. Tu as vu la rapidité ? Incroyable ! Là, c’est du temps réel. J’ai rien modifié. « Donne-moi la biographie de Victor Hugo. » On va tester. Bam ! La biographie de Victor Hugo en moins de 3 secondes !
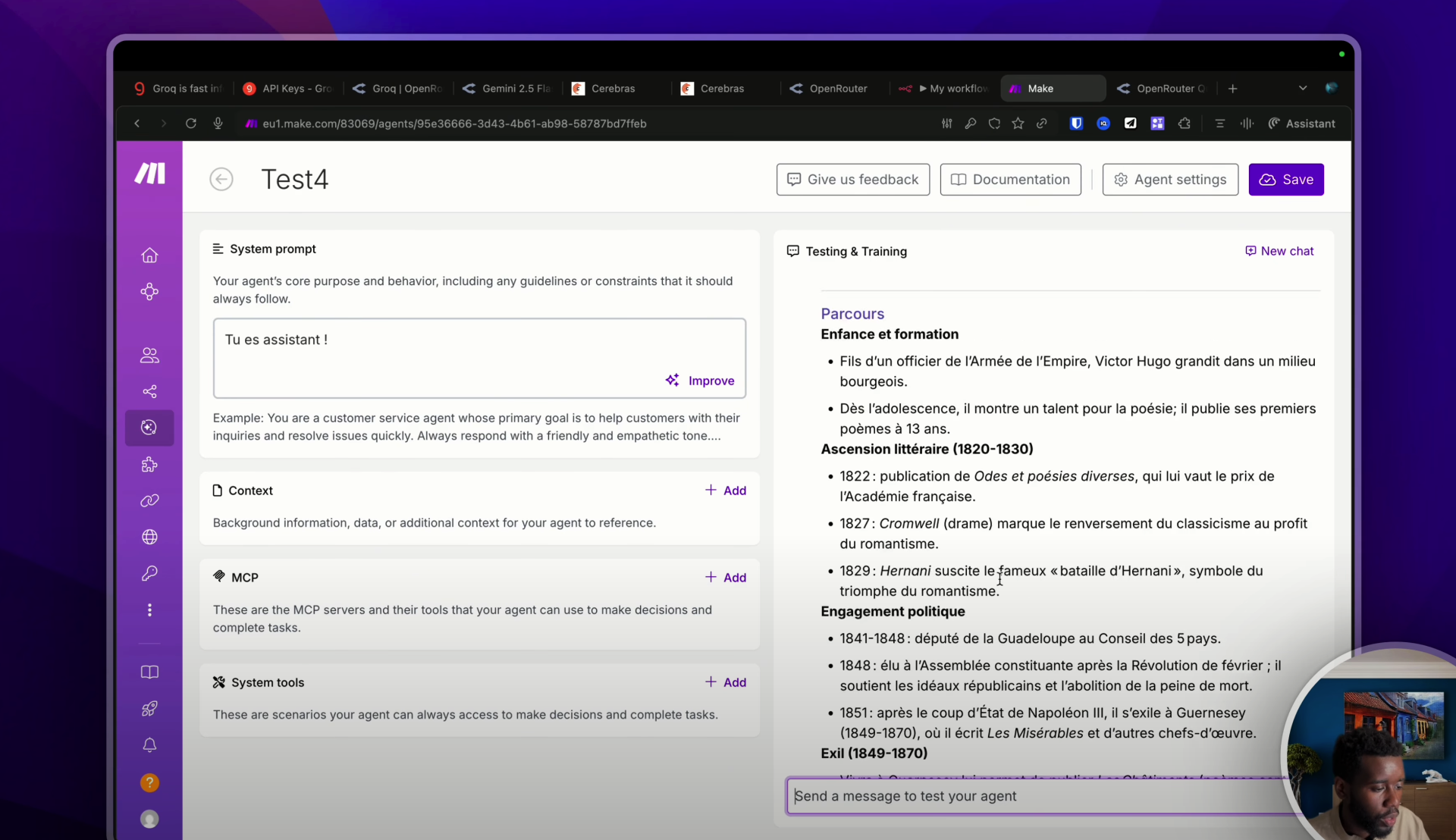
Et pour finir, il te suffira de sauvegarder, de créer un nouveau scénario et d’appeler ton agent comme ceci : « Make an agent, run an agent » et de prendre le « Test numéro 4 » pour utiliser un agent IA propulsé par Cerebras.
Conclusion
Maintenant, tu as toutes les clés en main pour utiliser ces fusées dans tes automatisations, dans tes applications. D’ailleurs, si tu es développeur, il te suffira de te rendre dans les documentations de ces plateformes, donc Open Router ou Groq, afin de connaître tous les endpoints dédiés.
J’espère que la vidéo t’a plu. N’hésite pas à me laisser en commentaire tes questions ou tes suggestions. D’ailleurs, si tu veux plus de contenu de ma part, il y a un lien dans la description pour t’abonner à ma newsletter ou pour rejoindre ma communauté.
FAQ
Q1 : Qu’est-ce que le TTFT et pourquoi est-il important pour la rapidité d’une IA ?
R1 : Le TTFT, ou « Time To First Token », mesure le temps que met une IA pour commencer à répondre. Plus il est court, plus l’IA donne l’impression d’être instantanée, améliorant ainsi l’expérience utilisateur.
Q2 : Comment Groq et Cerebras parviennent-ils à être plus rapides que d’autres modèles d’IA ?
R2 : Contrairement à l’approche traditionnelle des GPU, Groq et Cerebras ont créé des puces spécialement conçues pour l’intelligence artificielle : la LPU pour Groq et la WSE pour Cerebras, permettant des réponses hypers soniques.
Q3 : Puis-je utiliser les modèles de Cerebras si je ne suis pas une grande entreprise ?
R3 : Oui, même si Cerebras vise principalement les entreprises, tu peux accéder à leurs modèles via des fournisseurs tiers comme Open Router ou Hugging Face, en utilisant leurs API et une tarification au token.
Q4 : Comment puis-je m’assurer que Make ou N8N utilise bien Cerebras via Open Router ?
R4 : Pour t’assurer que Cerebras est bien le fournisseur utilisé, tu dois configurer « Allowed Providers » sur « Cerebras » et activer « Always enforce » dans les paramètres de ton compte Open Router. Tu peux ensuite vérifier l’onglet « Activity » sur Open Router pour confirmer le fournisseur de tes requêtes.